

Стендап Сьогодні
📢
Канал в Telegram @stendap_sogodni
🦣
@stendap_sogodni@shevtsov.me в Федиверсі
13.09.2023
Профілювання С-коду всередині Ruby
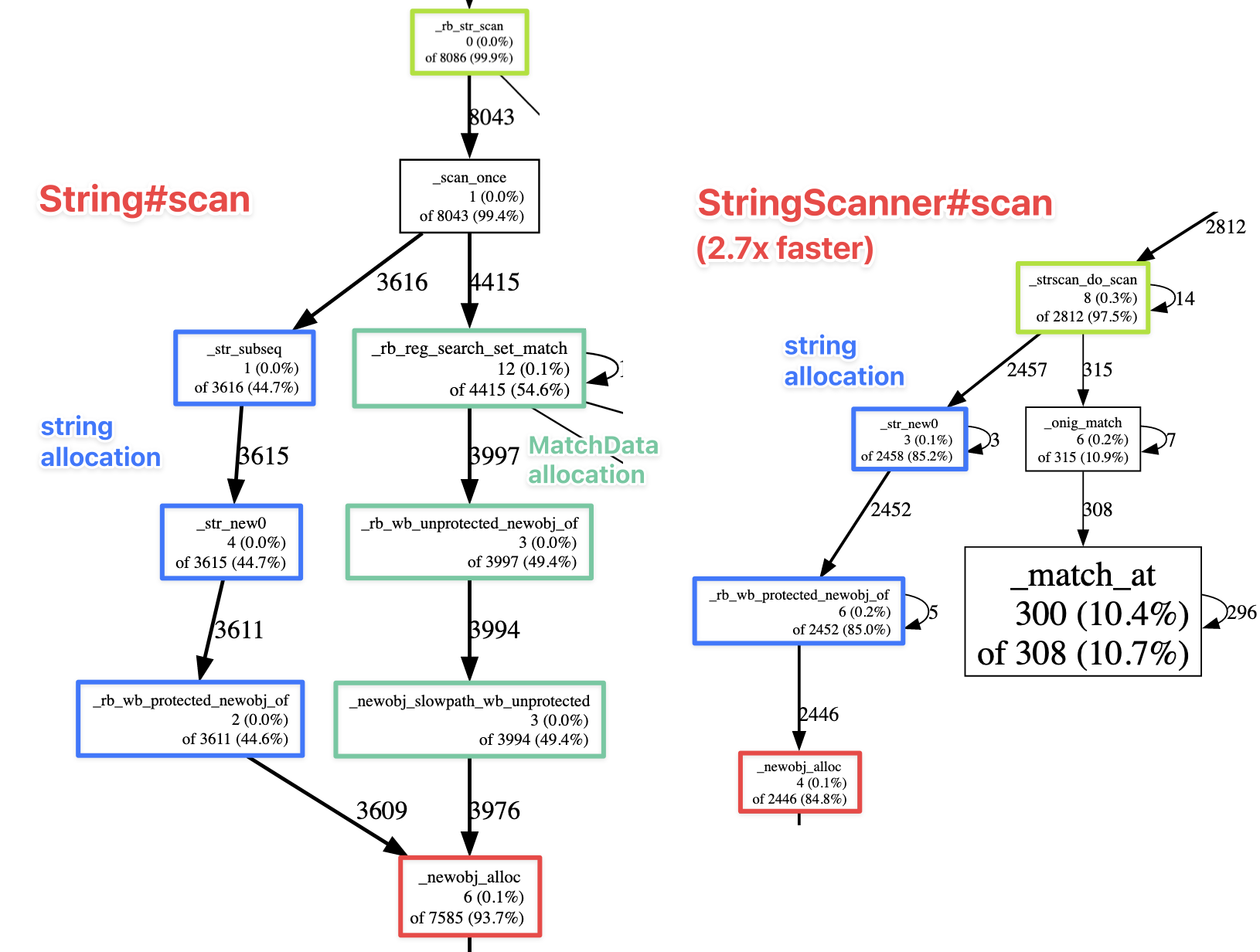
String#scan витрачає половину часу на створення обʼєктів MatchData
Докопався до правди по вчорашньому питанню. Для цього треба було знайти, як профілювати не Ruby-код, а C-код, який складає методи, які ми порівнюємо.
Вдалося це зробити за допомогою цієї статті. Потрібно встановити інструменти профілювання GPerfTools - вони є у Homebrew. А потім скомпілювати Ruby з додаванням профілювання. На моєму Macbook M2 для цього достатньо увімкнути дві опції:
env RUBY_CFLAGS='-fno-omit-frame-pointer' LIBS="-lprofiler" asdf install ruby 3.2.1
# Потім:
env CPUPROFILE="out.profile" ruby payload.rb
pprof $(asdf which ruby) out.profile --svg > out.svg
Результати можна побачити на ілюстрації зверху. Обидві реалізації витрачають більшість часу у виділенні памʼяті. (Решта — це пошук регулярного виразу, який відбувається практично однаково.) Але там, де StringScanner просто бере довжину збігу та копіює від початку, String#scan викликає код, що створює обʼєкти MatchData, а з них вже отримує розташування та довжину збігів. Та, профілювання ясно показує, що саме виділення памʼяті для MatchData становить додаткові витрати часу, які ми бачили вчора.
Чому String#scan потрібні обʼєкти MatchData? Тому, що цей метод шукає фрагменти не тільки на початку, а й в будь-якому місці рядка. До того ж він підтримує регулярні вирази з підгрупами. А StringScanner розрахований на єдиний випадок використання. Маємо висновок: у програмуванні спеціалізація коду веде до його оптимізації.