

Стендап Сьогодні
📢
Канал в Telegram @stendap_sogodni
🦣
@stendap_sogodni@shevtsov.me в Федиверсі
12.08.2024
Двійкові дані в текст: дробові кодування
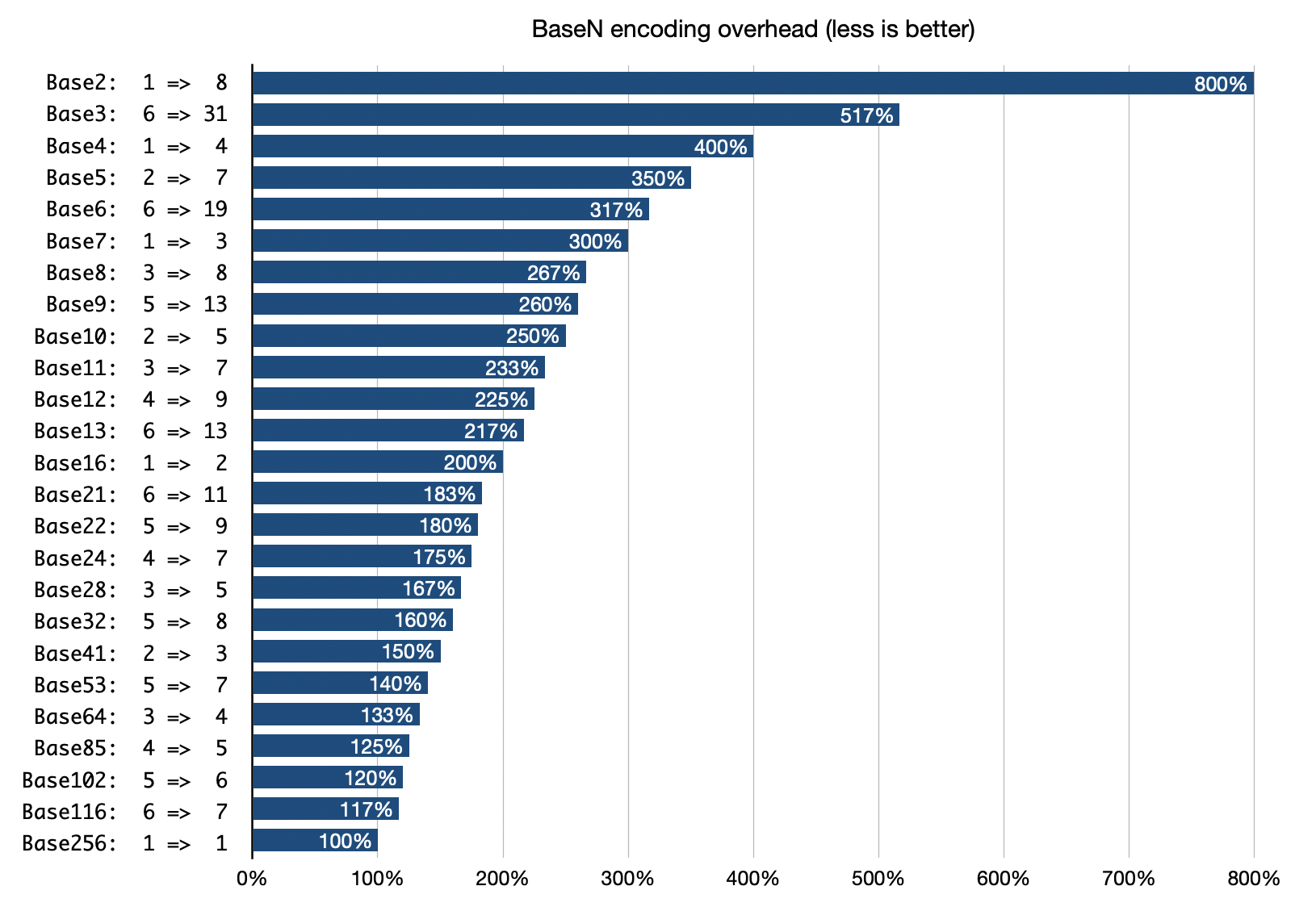
Зробив таку ілюстрацію. Скрипт тут
Нам не обовʼязково обмежуватись кодуваннями, де розмір словника є ступенем двійки. Це, звісно, суттєво спрощує операції та дозволяє робити декодування таким псевдокодом (для Base64):
three_bytes = lookup[c0] + lookup[c1] << 6 + lookup[c2] << 12 + lookup[c3] << 18
Але ж будь-який інший розмір словника також технічно можливий. Фактично ми впроваджуємо систему числення з основою, що дорівнює розміру словника, та переводимо наші двійкові дані в та з неї. Єдине, що відрізняє цей процес від шкільної програми: вхідна послідовність розбивається на фрагменти такого розміру, щоб вони влазили в 64-бітне число. (А ще краще — у 48-бітне, що не втратить точності в типі Double та не створить сюрпризів, наприклад, у JavaScript.)
Як тривіальний приклад, розглянемо Base10. Тут кожний символ має одне з 10 значень. Два символи: 100 значень. Три: 1000 значень. Це більше за 256 - значить, трьома символами Base10 можна закодувати один байт. Надлишок такого кодування аж 300%. Хоча насправді за 3 байти можна впоратись й у Base7 (де 343 можливих значень.) А з Base10 надлишок буде менше, якщо кодувати 2 байти (65536 значень) у 5 символів: тільки 250%.
…Якщо це узагальнити, можна прийти до ілюстрації вище. Вона показує надлишок для всіх основ від 2 до 256, але тільки тих, де він зменшується (що в Base64, що в Base65 3 байти даних кодуються в 4 символи.)
Що ми бачимо? Краще за Base64 буде тільки Base85 - який, як згадали в коментарях, використовує Git, а до того ж ще й PostScript та PDF. Як я розумію, тут вирішили, що розмір файлу важливіший за швидкість обробки. Наприклад, в Git у Base85 кодуються патчі - операції з патчами не такі часті, отже можна й почекати.
Наступне покращення наступає на Base102 - для такого вже доведеться відкусити декілька системних символів. Що робить наше “текстове кодування” не таким вже й текстовим. Гадаю, це пояснює, чому окрім Base64 та Base85 інших кодувань немає. (Ну як, немає… Base16 ми теж скрізь використовуємо!)